
理解c语言中的声明
在阅读优秀的 c 语言开源程式的时候,我们经常会看到各种复杂的声明,顿时会让我们怀疑人生,怀疑自己是否真的看得懂 c 语言。然而冷静三秒钟,透过现象看本质,发现牛人写的代码并不是“天书”, 也是很好懂的,关键是要冷静和耐心去阅读。
从“C Traps and Pitfalls”中的一个例子说起
(*(void(*)())0)()下面我们来一步步分析:
在阅读优秀的 c 语言开源程式的时候,我们经常会看到各种复杂的声明,顿时会让我们怀疑人生,怀疑自己是否真的看得懂 c 语言。然而冷静三秒钟,透过现象看本质,发现牛人写的代码并不是“天书”, 也是很好懂的,关键是要冷静和耐心去阅读。
(*(void(*)())0)()下面我们来一步步分析:
在之前的文章中,我们已经实现了一些 object handlers 来将我们的 ArrayBuffer 整合到 php 中。但是美中不足的是,我们的 ArrayBufferView 并不支持迭代器操作。也就是它不能像 php 中的数组那样使用foreach来遍历。
那么,我们接下来就来看看迭代器在内核中是如何实现的,并且给我们的 ArrayBufferView 也增加一个迭代器。
内核中的迭代器跟用户端的IteratorAggregate接口功能是一样的。一个具有迭代功能的类都有一个get_iterator处理器,它会返回一个zend_object_iterator *类型的结构,该结构定义如下(位于 phpsrc/Zend/zend_iterators.h 中):
struct _zend_object_iterator {
void *data;
zend_object_iterator_funcs *funcs;
ulong index; /* private to fe_reset/fe_fetch opcodes */
};其中的index成员就是内核中用以实现foreach的,它的值会在每次迭代后增加。funcs成员包含了不同的迭代操作:
在前面的博文中,已经介绍过一些 object handlers 了,也特别介绍了如何通过指定 handlers 来创建一个自定义的结构和使用clone_obj来对自定义的结构进行克隆操作。
然而,这只是开始:在 php 中,几乎所有的对象操作,都可以通过 object handlers 来实现,而且所有的魔术方法和魔术接口在内核中都是实现了对应的 object handler。此外,
一些 handlers 并没有开放给用户端的 php,例如,内部类可以自定义类的比较操作,而使用 php 代码是无法实现的。
由于 php 中有很多不同的 object handlers,这里只挑几个来讨论,其它的只给出简单的说明。
下面列举出 php 中主要的 26 个(php5.6 中为 28 个)object handlers(位于 phpsrc/Zend/zend_object_handlers.h),并给出简要的说明。
zval *read_property(zval *object, zval *member, int type, const struct _zend_literal *key TSRMLS_DC)
void write_property(zval *object, zval *member, zval *value, const struct _zend_literal *key TSRMLS_DC)
int has_property(zval *object, zval *member, int has_set_exists, const struct _zend_literal *key TSRMLS_DC)
void unset_property(zval *object, zval *member, const struct _zend_literal *key TSRMLS_DC)
zval **get_property_ptr_ptr(zval *object, zval *member, const struct _zend_literal *key TSRMLS_DC)上述 handlers 分别表示__get,__set,__isset,__unset方法。get_property_ptr_ptr等同于__get返回一个引用类型。zend_literal *key作为这些函数的参数
起到优化作用,例如它包含了一些将属性名进行 hash 计算的结果。
ArrayBuffer 又叫二进制数组,是一个用来表示通用的,固定长度的二进制数据缓冲区。你不能直接操纵 ArrayBuffer 的内容, 而是创建一个表示特定格式的 buffer 的类型化数组对象(也叫做数据视图对象)来对 buffer 的内容进行读写操作。
我最早了解 ArrayBuffer 是从 JavaScript 开始的,具体的用法和 api 可以参考JavaScript 标准库--ArrayBuffer
那么接下来,我们就给 PHP 扩展一个简单的 ArrayBuffer,顺便巩固一下php 扩展开发之自定义对象的存储。
ArrayBuffer是一个非常简单的对象,它只需要申明并存储一个buffer和它的长度即可:
typedef struct _buffer_object {
zend_object std;
void *buffer;
size_t length;
} buffer_object;接下来我们来实现它的create和free handlers,有了前面的基础,这个实现也是及其简单的:
对于 php 扩展开发,很多人可能已经不那么陌生了,zend 引擎为了们提供了非常丰富了函数和 macro,来帮助我们很快速的创建一个标准的 php 类,然而,当我们在使用自定义的数据结构(struct), 并想把我们自己定义的数据结构封装成 php 的类的时候可能就会有些困惑,因为我们都知道 php 中的所有变量都是通过 zval 来存储的,而我们自定义的数据结构要怎样才能和 zval 实现完美的对接呢? 以前我通常采用的一种方式就是使用 zend 引擎提供的资源类型,因为资源类型的封装中包含了通用的数据类型,而且有很丰富的函数来操作资源,所以使用起来很简单也很方便。然而,强大的 zend 引擎真的没有其他方式扩展数据结构了吗?当然不是!下面就来介绍一个更加优雅的方式。要弄明白,首要要搞清 php 内核是如何创建对象的。
我们首先来探讨下如何创建一个 PHP 对象。为此我们将会用到object_and_properties_init之类的一些宏。
// 创建一个SomeClass类型的对象,并且把properties_hashtable中的变量作为其属性值
zval *obj;
MAKE_STD_ZVAL(obj);
object_and_properties_init(obj, class_entry_of_SomeClass, properties_hashtable);
// 创建一个没有属性的对象
zval *obj;
MAKE_STD_ZVAL(obj);
object_init_ex(obj, class_entry_of_SomeClass);
// = object_and_properties_init(obj, class_entry_of_SomeClass, NULL)
// 创建一个stdClass的对象
zval *obj;
MAKE_STD_ZVAL(obj);
object_init(obj);
// = object_init_ex(obj, NULL) = object_and_properties_init(obj, NULL, NULL);
在上面的例子中,最后一种情况下,当你创建一个stdClass的对象后,通常将会给它添加属性。这时如果使用
zend_update_property之类的函数,是不起作用的,取而代之的是add_property宏函数:
哈希表又叫散列表,是实现字典操作的中有效数据结构。通常来说,一个 hash table 包含了一个数据,其中的数据通过 index 来访问。 而 hash table 的基本原理就是通过 hash 函数建立起所有可能的 index 与其对应的位置的联系。一个 hash 函数接收一个 key,返回其 hash code, key 的类型是可变的,而 hash code 是一个整型。
由于计算一个 hash 值和通过 index 访问一个数据都是常量级的时间复杂度,所以我们可以通过这中特性实现常量级时间复杂度的查找。 如果一个 hash 函数能够保证不会有两个不同的 key 生成相同的 hash 值,那么这样的 hash table 就被称为是直接定址。然而,这只是一想法而已, 实际上这种 hash table 在现实中却是不常用的。
链式 hash 表从本质上来讲,就是一个存放了一组链表的数组。每个链表可以看做是一个槽,我们把元素通过 hash 函数找到一个 hash 值,然后把元素的值 放入到数组中与改 hash 值对应的槽中。
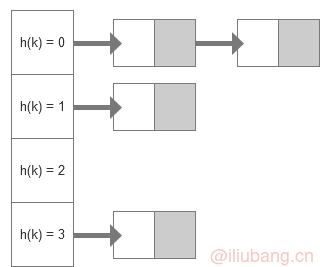
当有两个 key 被 hash 到了同一个位置,就会产生冲突。链式 hash 表有一种简单的冲突解决办法:当冲突产生时,元素被简单的放在同一个槽里。这样做可能带来的问题就是, 如果在同一个位置上出现很多冲突,这个槽就会变得越来越长,这样当我们访问这个槽中的元素的时候,所花的时间也就会越来越长。
前面系统研究了 JNI 的相关操作,下面就来小试牛刀,做一个实际的练习。
记得去年我曾经用 C 语言写过一个 PHP 的 md5 扩展函数,那么今天就花一点点时间用 JNI 来实现一遍吧。
不过这里可要提前声明了,虽然是实现 md5 函数,但是这里并不会从头写 md5 算法,而是投机取巧使用到了 linux 内核提供的crypto库。
废话不多说,首先来写一个 Java 类
MyString.java
public class MyString {
static {
System.loadLibrary("mymd5");
}
private String value;
public native String md5();
public MyString(String value) {
this.value = value;
}
}然后生成头文件,并实现 c 代码:
JNI 中定义了一下类型来对应到相应的 Java 的数据类型:
1. Java 基本数据类型: jint,jbyte,jshort,jlong,jfloat,jdouble,jchar,jboolean分别对应 Java 中的int,byte,short,long,float,double,char和boolean。
2. Java 引用类型:
jobject对应java.lang.object。同时也定义了下列子类型:
jclass对应java.lang.Classjstring对应java.lang.Stringjthrowable对应java.lang.Throwablejarray对应 Java 中的数组。Java 中的数组由 8 种基本数据类型和一个Object类型派生二来,所以 JNI 中也存在jintArray,jbyteArray,jshortArray,jlongArray,jfloatArray,jdoubleArray,
jcharArray,jbooleanArray和jobjectArraynative 函数接收和返回上述的 JNI 类型数据。如果 native 函数需要操作它自己的数据类型(如 c 语言中的 int, char *),那么就需要在 JNI 类型和本地类型之间做相应的转换。
简而言之,native 函数的编写流程大致为:
从上述流程可以看出,编写 JNI 程序主要的挑战在于数据类型之间的转换,然而 JNI 中提供了很多转换函数来帮助我们完成相应的操作。
JNI 是一个 c 语言的接口,c 语言并不支持 OOP 的特性(严格的说,OOP 是一种理念,这里只是从语言本身来说 c 语言不支持面向对象,实际上用 c 语言也可以写出面向对象风格的程序!),所以他们之间并不是真的通过对象来传递。
说明:参考文献地址 A Malloc Tutorial
malloc是干什么的?如果你连这个名字都没听过,那么你应该先去了解 Unix 环境下的 c 语言开发,然后再来阅读。对一个程序员而言,malloc是一个在 c 语言中用来分配内存的函数,但是大多数人并不知道它背后真正的原理,甚至有些人认为malloc是 c 语言的关键字或者认为它是系统调用。事实上,malloc是一个再简单不过的函数而已,而且只需要很少的操作系统相关知识就可以让我们彻底理解它的原理。
下面来一步步的实现一个简单的malloc函数,从而帮助我们理解其背后运作的原理。因为仅仅作为说明原理之用,所以这里实现的malloc不会太高效,但是足以说明原理。
什么是 malloc
malloc(3)是一个用来分配内存块的标准的 c 语言库函数。它遵循以下规则:
malloc至少分配所需字节数的内存;malloc返回其所分配内存空间(程序可以成功读写的空间)的指针;malloc分配,其他malloc调用不能再分配该内存块的任何部分,除非指向该内存块的指针被释放掉;malloc应该是可控的:他必须能够很快完成分配并返回;malloc同时应该提供重新分配内存块大小和释放内存的功能malloc函数必须遵循以下原型:
void *malloc(size_t size);其中size是所需要的内存大小。如果失败(没有足够的内存空间可以分配),应该返回NULL。